Dữ liệu luôn đóng vai trò trung tâm trong chiến lược phát triển của mọi doanh nghiệp. Để khai thác tối đa giá trị từ nguồn dữ liệu đó, bạn cần có một quy trình thu thập thông tin chính xác và hiệu quả. Quá trình này chính là web scraping. Trong bài viết dưới đây, HTH DIGI sẽ giúp bạn tìm hiểu web scraping là gì và những khía cạnh quan trọng xoay quanh nó.
Web scraping là gì?
Về bản chất, web scraping là phương pháp tự động trích xuất dữ liệu từ một trang web và chuyển đổi sang một định dạng khác để thuận tiện cho việc sử dụng. Kỹ thuật này còn được biết đến với các tên gọi như site scraping hoặc data scraping.
Mục đích chính của web scraping là thu thập những thông tin cụ thể trên website và phục vụ cho các nhu cầu khác nhau. Ví dụ: công cụ so sánh giá vé máy bay sẽ dùng web scraping để tìm và hiển thị chuyến bay rẻ nhất, nhanh nhất cho người dùng.
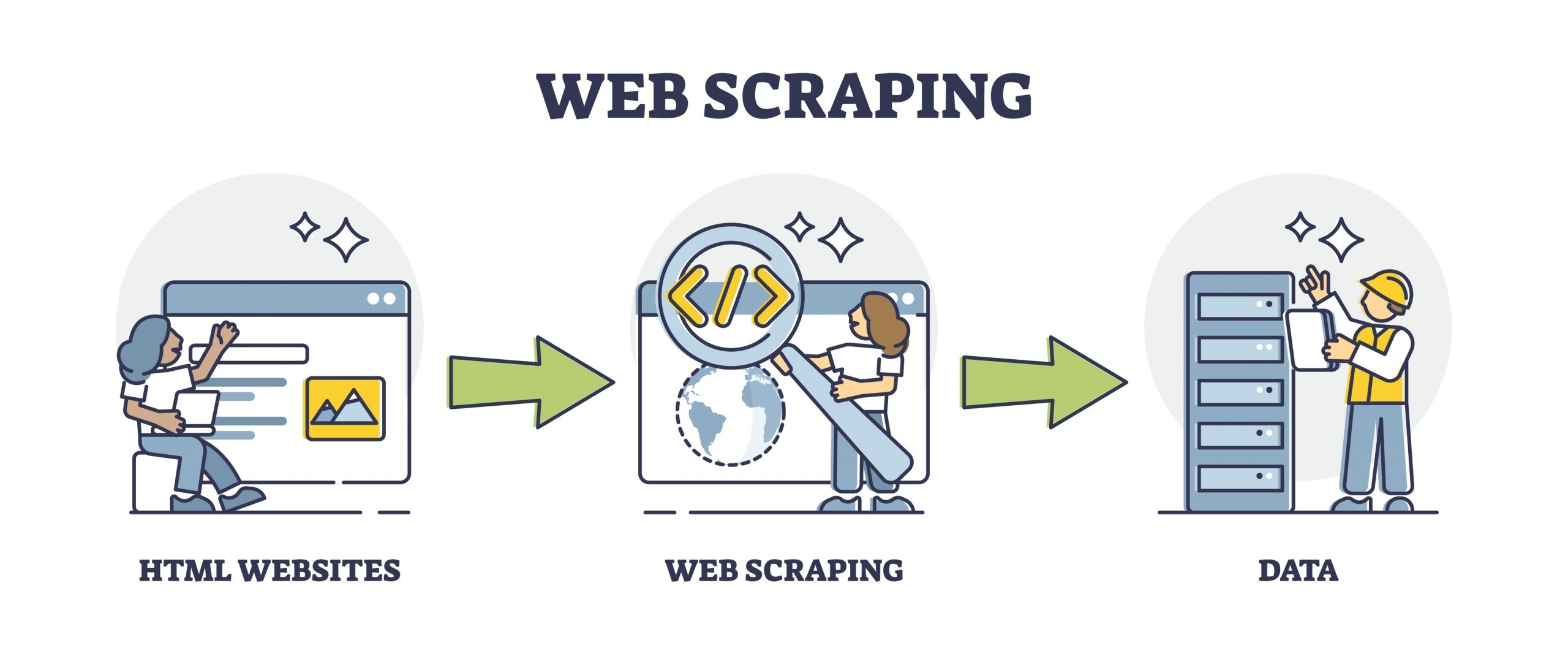
Khả năng ứng dụng của web scraping gần như vô hạn, tùy thuộc vào sự sáng tạo của con người. Vì lượng dữ liệu thu thập thường rất lớn, thông tin thường được xuất ra định dạng bảng tính như CSV, XLSX hoặc định dạng JSON nếu dùng cho API (application programming interface).
Quá trình thu thập này có thể được thực hiện thủ công bởi con người hoặc tự động nhờ các chương trình gọi là crawler.
Cơ chế hoạt động của web scraping
Quy trình cơ bản gồm ba bước:
-
Xác định nguồn dữ liệu – Bot crawler được cung cấp danh sách URL của các trang web cần thu thập.
-
Trích xuất thông tin – Bot truy cập cơ sở dữ liệu của website, tìm và lọc ra dữ liệu theo tiêu chí đã định sẵn.
-
Xuất dữ liệu – Kết quả được lưu lại ở định dạng bảng tính hoặc tệp dữ liệu để người dùng xử lý.
Nghe qua thì đơn giản, nhưng để thu thập dữ liệu đúng yêu cầu, lập trình viên cần tối ưu thuật toán lọc và xử lý dữ liệu.
Ứng dụng của web scraping
Công cụ tìm kiếm
Google, Bing hay Yahoo chính là những ví dụ tiêu biểu cho web scraping ở quy mô khổng lồ. Bot crawler của các công cụ này liên tục quét, trích xuất và phân tích nội dung trang web để phục vụ cho việc xếp hạng tìm kiếm.
Nghiên cứu thị trường
Web scraping hỗ trợ các doanh nghiệp thu thập dữ liệu từ nhiều nguồn, tạo nên một bộ thông tin hoàn chỉnh để phân tích xu hướng, dự đoán biến động thị trường và nghiên cứu hành vi khách hàng (customer insights). Nó có thể trích xuất dữ liệu từ các cuộc trò chuyện trên mạng xã hội để hiểu rõ hơn về tâm lý và nhu cầu của người tiêu dùng.
Theo dõi và so sánh giá cả
Từ giá vé máy bay, phòng khách sạn, thực phẩm cho đến cổ phiếu hay tiền điện tử – web scraping giúp các công cụ so sánh giá hoạt động nhanh chóng và chính xác. Nhà đầu tư, doanh nghiệp hay người tiêu dùng đều có thể hưởng lợi từ dữ liệu này. Ngoài ra, một số doanh nghiệp còn sử dụng web scraping để theo dõi giá của đối thủ và điều chỉnh chiến lược giá của mình.

Website tổng hợp tin tức
Các cổng thông tin và ứng dụng đọc tin cũng là những “người dùng” tích cực của web scraping. Họ thu thập bài viết từ nhiều nguồn báo khác nhau, sau đó hiển thị tập trung để người dùng tiện theo dõi.
Mặt tốt và xấu của web scraping
Web scraping mang lại nhiều lợi ích, nhưng nếu bị lạm dụng, nó có thể trở thành công cụ cho các hành vi không lành mạnh như:
-
Sao chép nội dung từ đối thủ
-
Lấy dữ liệu giá để phá giá thị trường
-
Khai thác lỗ hổng bảo mật, đánh cắp thông tin người dùng
-
Phát tán dữ liệu trái phép hoặc tống tiền
Vì vậy, các doanh nghiệp cần hiểu rõ rủi ro để áp dụng biện pháp bảo vệ.

Cách phòng tránh web scraping bất hợp pháp
-
Giám sát hành vi truy cập để phân biệt bot và người thật
-
Kiểm soát tài khoản mới tạo nhưng hoạt động bất thường
-
Yêu cầu xác nhận điều khoản hoặc nhập captcha
-
Cập nhật công nghệ bảo mật và bot protection mới nhất
Trên đây, HTH DIGI đã giải thích chi tiết web scraping là gì, nguyên lý hoạt động, ứng dụng và cả những nguy cơ tiềm ẩn. Đây là một công nghệ nền tảng cho nhiều công cụ và ứng dụng quan trọng, nhưng bạn cũng cần cẩn trọng để tránh bị lợi dụng theo cách tiêu cực.




